As a non-technical individual, I used to be at all times struggling to know the under-the-hood facet of purposes. It acquired higher over time: thanks to varied books, articles, meetups, my technical associates, and, in fact, one Java developer who can also be my husband 🙂

On this story, I want to advocate and evaluation one e-book that I believe is a should for everybody who doesn’t have a technical background or training (or has it, however feels uncertain in a working surroundings). That is the “Web Scalability for Startup Engineers” book by Artur Ejsmont. Though the e-book is about net software scalability, it truly explains the core ideas and elements of software program structure. I can’t let you know how the e-book is obvious and well-defined!
The story is totally primarily based on Artur Ejsmont’s experience and data. I don’t fake to be a technical professional which I’m not (no less than for now 😏).
What I share on this story could be very restricted. When studying the e-book, I ready the summary for myself that took 20 Google Docs pages. If you wish to enhance your understanding of software program structure, I’d advocate studying the e-book, making ready the summary, and discussing what you might have discovered with a technical good friend or colleague.
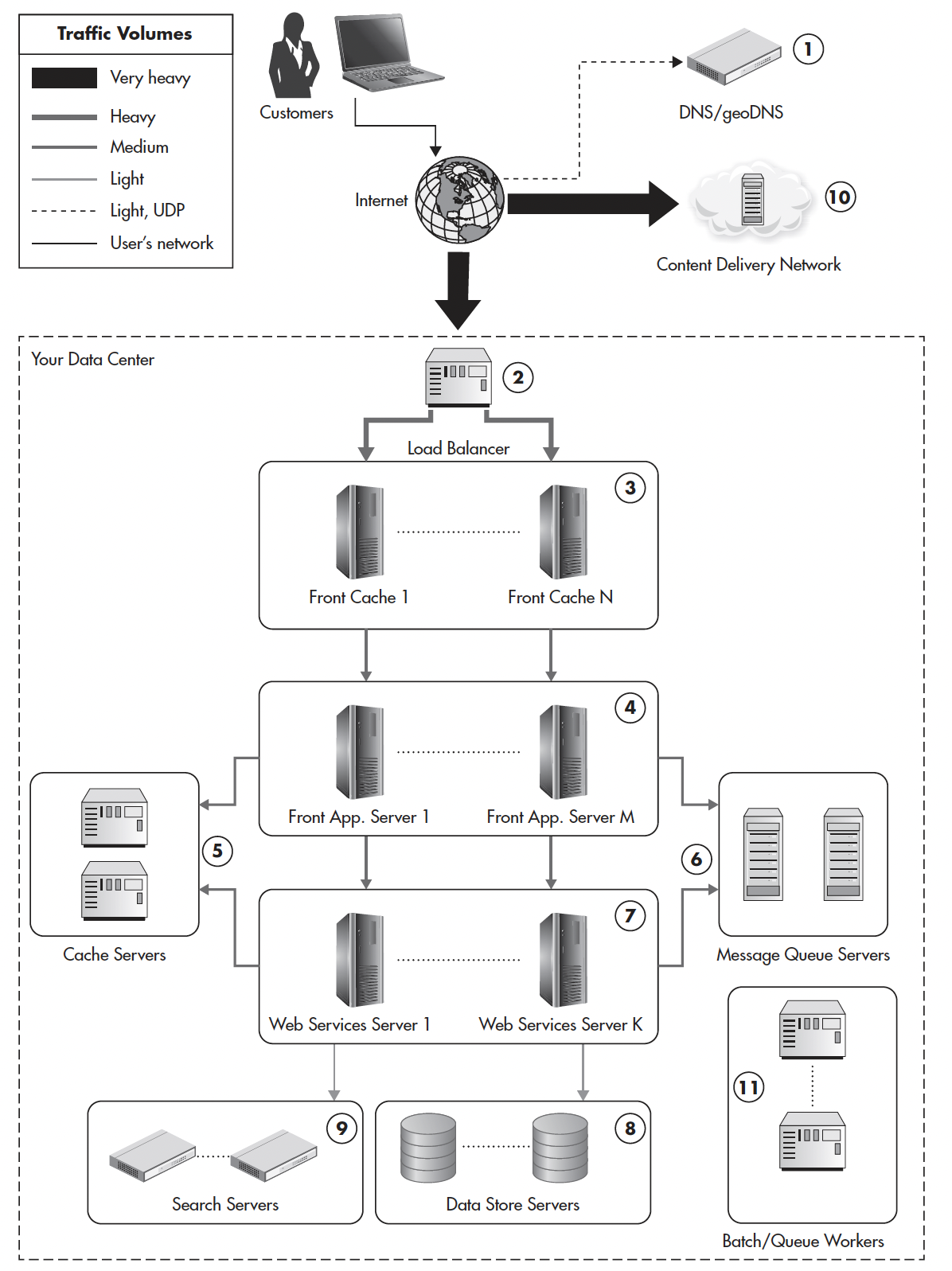
0. Clients: the tip customers of your net software.
1. Area Title System (DNS): defines an IP handle (the handle of the server which can course of a consumer request) primarily based on a website title (e.g. olgamitroshyna.com).
2. Load Balancer: distributes site visitors amongst a number of servers to share the load.
3,5. Cache: shops knowledge to serve consumer requests quicker.
4. Entrance Software (Entrance-end): that is the consumer interface, an software pores and skin, a presentation layer.
6. Message Queue: shops consumer requests for additional processing by net providers.
7. Net Companies (Again-end): the place the enterprise logic (app performance) lives.
8. Information Retailer: the place net providers write knowledge and browse knowledge from.
9. Search Engine: liable for advanced search queries {that a} knowledge retailer can’t deal with effectively.
10. Content material Supply Community (CDN): shops static information like photographs, CSS, and JavaScript information to serve consumer requests quicker.
11. Queue Employees: extra servers to course of requests (i.e. messages) from a message queue.
Entrance-end layer elements are:
- DNS;
- CDN;
- Load balancer/reverse proxy. May be one among three varieties:
a) A hosted service (e.g. Elastic Load Balancer by Amazon);
b) A self-managed software-based load balancer (e.g. Nginx);
c) A {hardware} load balancer. - Entrance-end net servers (a presentation & back-end outcomes aggregation layer; applied sciences: PHP, Python, Groovy, Ruby, or JavaScript (Node.js)).
It’s additionally vital to know that the front-end layer shops the details about the HTTP session (the information a few consumer) through: a) cookies; or b) an exterior knowledge retailer; or c) a load balancer if so of a sticky session: the load balancer must ensure that requests with the identical session cookie at all times go to the server that originally issued the cookie.
Choices to implement an app:
- Construct a monolithic app, then add net providers based on the enterprise wants;
- Observe an API-first method: all purchasers (cell app, desktop web site, cell web site, and many others.) use the identical API interface when speaking to an internet software;
- Mixture of these two above.
Forms of net providers:
- Operate-centric
> The flexibility to name features’ strategies on distant machines with out the necessity to know the way these features are carried out;
> Instance: SOAP (makes use of XML and HTTP protocol); SOAP is extra advanced & safe than REST, REST is extra light-weight when it comes to documentation than SOAP. - Useful resource-centric (REST + JSON)
> Sources are handled as objects, and 4 operations may be carried out on the objects: learn, create, replace, and delete (GET, POST, PUT, DELETE);
> REST requires authentication to entry assets (OAuth 2);
> Depends upon transport layer safety (HTTPS).
Scaling REST net providers:
- Into useful items / useful partitioning
> A strategy to break up a service into smaller, impartial net providers, the place every net service focuses on a selected performance;
> There is usually a few dependencies between net providers — and that’s okay (e.g. between a consumer (UserProfileService) and a product catalog (ProductCatalogService) when a consumer saves some merchandise from a catalog);
> Every net service may be scaled independently;
> Companies integration could also be difficult;
> The writer recommends utilizing the service-oriented structure and net providers solely when a tech crew grows above 10-20 engineers. - Including clones
- HTTP protocol caching
> When GET responses are cached (a response is returned from the cache quite than asking an internet service for the response).
- Including extra clones/servers (the best, least expensive choice);
- Division by performance (servers specialization, represents services-oriented structure (SOA); requires extra effort; functionalities are restricted);
- Division by knowledge (please see “Information layer” paragraph under).
Conventional scaling — vertical (shopping for stronger servers, including RAM, extra exhausting drives, and many others.).
Scaling a relational knowledge retailer (e.g. MySQL):
- Replication
> Having a number of copies of the identical knowledge saved on completely different machines;
> Have to sync the state of two servers: supply & duplicate;
> Information modification — solely through a supply server, however learn queries may be distributed amongst replicas;
> Challenges of replication: a) scaling solely reads (glorious for read-heavy apps); b) not a strategy to remedy the issue of an actively rising knowledge set; c) replicas can return outdated knowledge. - Information partitioning / sharding
> Division of a knowledge set into smaller items (no must course of the complete knowledge set);
> Sharding key is a criterion for partitioning (e.g. we now have customers in a web-based store, a consumer id can symbolize a shard, so any consumer info like orders is saved in that shard);
> Disadvantages: a) provides a major quantity of labor and complexity; b) you can’t execute queries throughout a number of shards; c) relying on the way you map from the sharding key to the server quantity, it is likely to be troublesome so as to add extra servers to your infrastructure;
> Azure SQL Database Elastic Scale is a ready-to-use resolution for sharding.
Scaling with NoSQL (e.g. Cassandra, Redis, MongoDB, Riak, CouchDB):
Eric Brewer’s CAP theorem: it’s inconceivable to construct a distributed system that will concurrently assure Consistency, Availability, and Partition tolerance.
- Consistency: the identical knowledge turns into seen to all the nodes on the similar time.
- Availability: all accessible nodes must course of all incoming requests and return a sound response.
- Partition: the cluster should proceed to work regardless of any variety of communication breakdowns between nodes within the system.
Which means solely 2 of three attributes may be met at a time. E.g. MongoDB trades excessive availability for consistency, it’s a CP knowledge retailer. Cassandra is an AP knowledge retailer — it delivers availability and partition tolerance, however can’t ship consistency on a regular basis.
Present pattern: utilizing the useful partitioning of the net providers layer and completely different knowledge shops primarily based on the enterprise wants.
- Used to extend efficiency and scalability as a result of it returns the ready-to-use outcomes;
- Attempt to obtain the next cache hit ratio (what number of occasions you’ll be able to reuse the identical cached response);
- Caching is nice for apps with many reads and could also be ineffective for the apps with many writes;
- Any caching may be added at a later stage if wanted.
HTTP-based cache — read-through caches (it signifies that a consumer speaks to the cache, and provided that the cache can’t reply to a consumer, it asks the net service).
Forms of HTTP-based cache:
- Browser cache
> We retailer knowledge within the browser. - Caching proxies
> A server is normally put in in a neighborhood company community or by the Web service supplier (ISP). - Reverse proxies (e.g. Nginx)
> Positioned in your individual knowledge heart to scale back the load put by yourself net servers;
> A superb strategy to scale. - CDNs
> Used to cache static information like photographs, CSS, JavaScript, movies, PDF (however may serve dynamic content material if wanted).
Customized object caches:
- Object caches on the consumer facet
> Saved on the consumer’s machine. - Caches co-located with code
> Positioned on net servers (FE or BE);
> Objects may be cached straight in: a) the applying’s reminiscence/RAM; b) shared reminiscence (a number of processes operating on the identical machine might entry them); c) a caching server may be deployed on every net server as a separate software (for tiny net apps). - Distributed object caches
> Redis, Memcached
Synchronous processing — the caller sends a request and waits for the response earlier than persevering with its personal work. You’ll be able to’t construct fashionable responsive apps utilizing synchronous processing.
Asynchronous processing —a consumer can end its personal job with out figuring out if the request was processed or not, a “fire-and-forget” precept.
Message queues are an asynchronous processing know-how:
- Message producers — part of the consumer code, create a message and ship it to a message queue.
- Message queues — the place messages are despatched and buffered for customers;
- Message customers — obtain and course of messages from a message queue. Forms of message customers: a) cron-like (pull messages from the queue); 2) daemon-like (a push mannequin).
Messaging platforms:
- Amazon Easy Queue Service (SQS) (easy, pragmatic; a superb resolution for early-stage startups);
- RabbitMQ (gives many options (incl. advanced routing), quite easy, versatile);
- ActiveMQ (Java-based, a lot decrease latency, much less versatile routing, may be delicate to massive spikes of messages being revealed).
- Not a request/response mannequin, elements announce occasions which have already occurred (as an alternative of requesting work to be accomplished);
- Occasion is an object or a message that signifies one thing has occurred;
- We’ve publishers and customers that don’t know something about one another —they know simply the format and that means of the occasion message.
- A full desk scan is an odd search (you want to scan the complete knowledge set to search out the row you’re in search of);
- Indexes are used to hurry up the search:

- As for knowledge fashions, a relational knowledge mannequin is the illustration of tables which have relations. In a nonrelational knowledge mannequin, you concentrate on use circumstances and design the corresponding queries, e.g. return a group of merchandise (and that’s normally a JSON with the record of merchandise).
- It’s beneficial to make use of engines like google for advanced search queries. They normally use the inverted index which permits looking for phrases or particular person phrases. The ready-to-use engines like google are: Amazon CloudSearch, Azure Search, Elasticsearch, Solr, Sphinx.
Scalability is not only concerning the structure, it’s additionally about:
- Automation of assorted processes (whether or not it’s testing, construct and deployment processes, monitoring and alerting, or log aggregation);
- Scaling your self:
> Work smarter, not more durable;
> Keep away from extra time because it results in psychological issues and burnout;
> Handle your duties by prioritization, perceive their actual worth;
> Construct easy, minimalistic performance;
> Delegate;
> Share data, collaborate;
> Use Third-party providers and don’t reinvent the wheel;
> Negotiate deadlines;
> Launch in small chunks, collect suggestions, don’t develop in a vacuum;
> Create small cross-functional autonomous groups of 4–9 individuals for explicit product areas (e.g. a crew round a checkout performance);
> Maintain all of your venture procedures and requirements versatile as they restrain creativity and innovation;
> Align groups, set widespread objectives, and construct a superb engineering tradition;
> And far more helpful recommendation!
To be trustworthy, I used to be relieved after studying “Net Scalability for Startup Engineers” e-book by Artur Ejsmont as a result of I heard a lot concerning the software program structure and numerous applied sciences at work, however I at all times felt like “I don’t utterly get it”. I desired to dive deep. And I’m so glad that it has occurred!
However there’s nonetheless a lot to be taught 🤓
Thanks for studying my quick abstract (it’s actually very quick because the e-book has far more useful info), hope you loved my story and can benefit from the e-book!
See you subsequent time!
Related Posts

5 Lifelong Lessons from The Magic of Thinking Big by David Schwartz
The Magic of Thinking Big. initially revealed in 1959Once I…

Book Review : The Alchemist by Paulo Coelho
I'm not an avid reader however of late I've been…

5 Practices from Deep Work by Cal Newport That’ll Change Your Life
Deep Work by Cal Newport, revealed January 2016Cal Newport would…